Data Lifecycle Management (DLM)
Overview
Data Lifecycle Management (DLM) is a policy- based approach to manage the access, compliance and disposition requirements of data throughout its lifespan. Understanding that data is not created or remains equal over time, DLM enables us to manage different sets of data based on needs. That is, DLM enables to i dentify, organize, classify, and index data accordingly, thereby providing an enhanced review experience. This approach also enables in disposing irrelevant data from Enterprise Archive.
The value DLM offers are:
Classify and organize data automatically,
Meet record-keeping demands more flexibly and effectively, using WORM or Operational storage, as needed,
Leverage legally defensible disposition (at scale), Privileged Delete to reduce risk (currently unavailable), and so on.
Important
DLM is not enabled by default, contact Smarsh Support to enable DLM. DLM must be enabled in both Archive Management and Case Management individually.
Concept
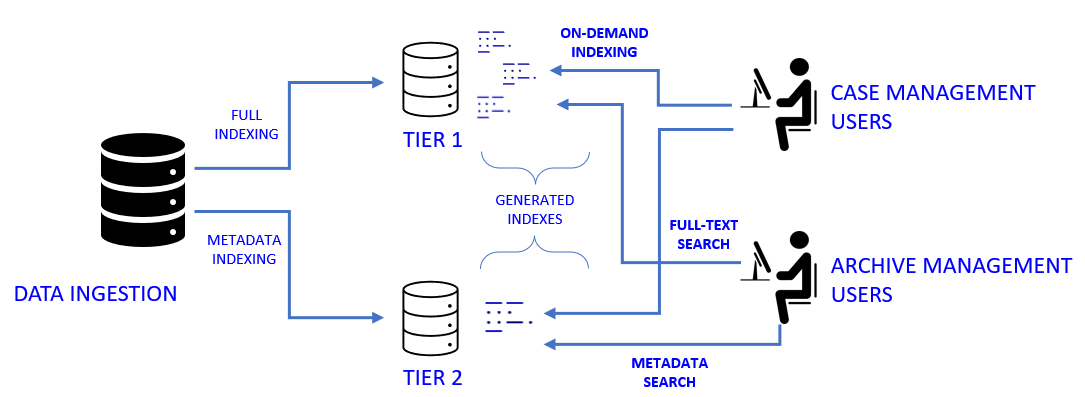
DLM provides an ability to manage the lifecycle of the ingested documents. Documents ingested and archived into Enterprise Archive are now indexed in two different tiers from where the documents are fetched when searched :
Tier 1, where Enterprise Archive indexes the entire communication (from ingested data ( full-text)) thereby allowing you to search into the entire content including body and attachments. Data from this tier is fetched when you perform a search in all Enterprise Archive applications, such as Archive Management, Case Management, and Supervision.
Tier 2, where Enterprise Archive indexes just the headers (or metadata) of ingested communication thereby allowing you to search based on date-range, x-headers, and keyword searches limited to Subject . Data from this tier is fetched when you perform a search in Archive Management and Case Management - Collect workspace.
This model of archive tiering is to reposition Enterprise Archive away from indexing everything and shift towards on-demand indexing, thereby enhancing the performance of the platform and enabling an efficient method to manage high-volume data.
On-Demand Indexing
On-Demand Indexing is a solution to reduce the index footprint by enabling the search query to fetch data between Tier 1 or Tier 2, based on different requirements and use-cases. That is, Enterprise Archive creates indexes based on certain demands. For example, when a case manager or a researcher collects a document into a case, Enterprise Archive creates indexes, which are called on-demand indexes.
For more information, see