FAQs
The following are Frequently Asked Questions (FAQs) in Enterprise Archive application:
Search
A Network refers to the source of archived communication. For example, MS Teams, Slack, Journal, Zoom, and so on. The Network filter in the Search page allows you to search for communications archived from a specific networks. By default, Enterprise Archive searches for communications from all the networks recorded.
A Communication Channel refers to the mode of communication within a network. For example, emails, collaboration, chat, voice, videos, blogs, and so on, which can be from one or more networks. The Communication Channels filter in the Search page allows you to s earch for communications archived from specific communication channels or modality of communication. By default, Enterprise Archive searches for communications from all the channels recorded.
Yes, phrases can be searched using List of Terms section.
Phrase searches can be performed without using double quotes.
It is advisable not to use single or double quotes when performing phrase searches in the List of Terms section.
When a phrase is expected to match results in exactly the same order, please use them in a single continuous line without using single or double-quotes.
Note
While the single quotes do not change the result set, double quotes end up breaking the phrase in individual words and the results contain all documents having at least one of these words, thus returning a much larger set of results.
The application search and indexing behavior is explained below and consists of the following components:
Enterprise Archive Index Store: Enterprise Archive indexes all the entries that a user can input. These entries are classified as keyword or text. Keyword entries are user inputs that should be searched as is, without analyzing them. Analyzing is the process of stripping (or transforming) user entries by tokenizing them, converting to lowercase, ASCII folded and so on. Text type fields are analyzed and any of the above actions are performed on them. Text fields refer to user content such as subject, body, and attachment text. All other user entries are keywords.
Querying the Enterprise Archive Index Store: Querying refers to searching for specific terms or phrases that are indexed. Anything that is not indexed cannot be searched in Enterprise Archive. Querying for special characters will not return any search results as the application analyzes text inputs and strips them of special characters.
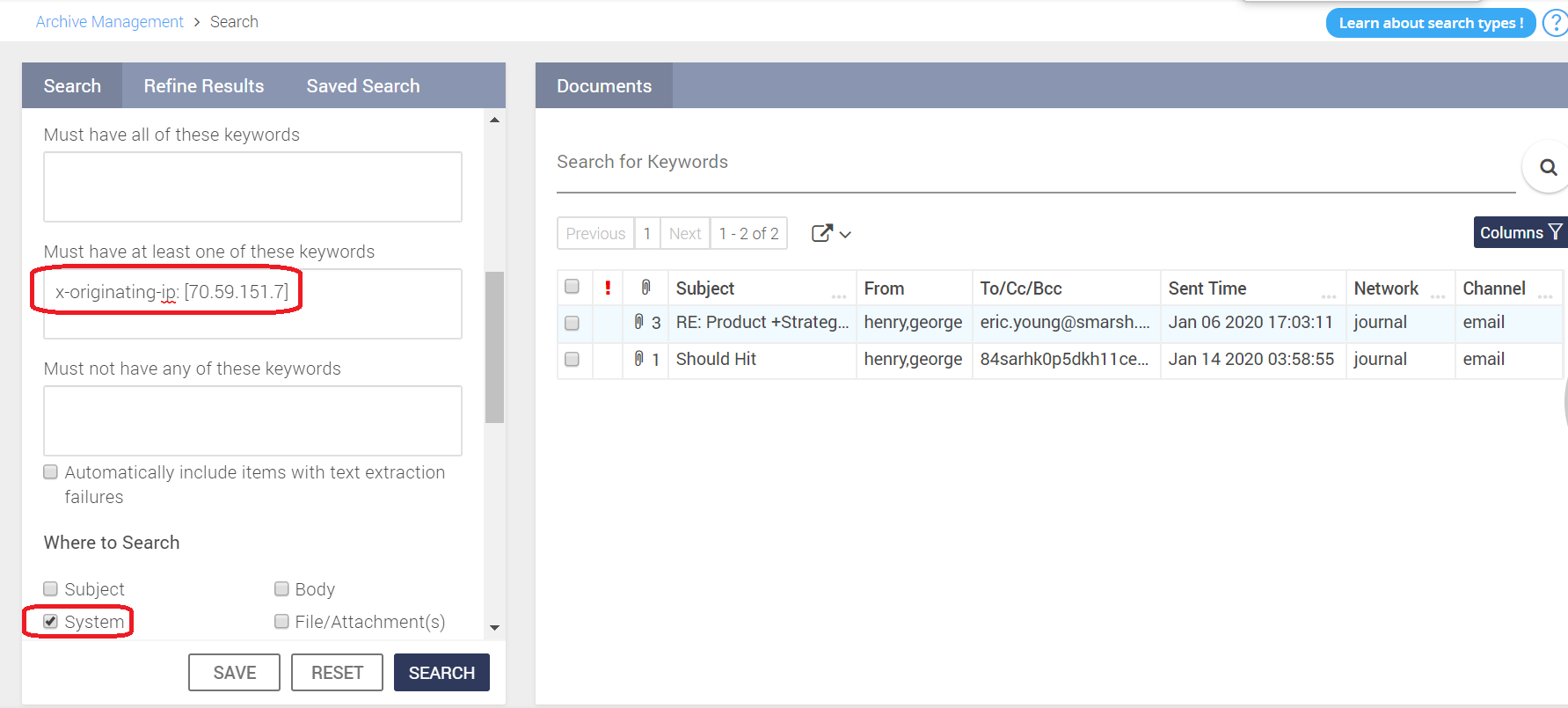
To search for specific X-header values in email conversations:
Navigate to Archive Management > Search.
Click and expand Words/Phrases.
Specify the X-header or the complete X-header name and value together in the Must have at least one of these keywords under the List of Terms section.
Enable the System check box in the Where to Search pane.
Exports
When you export documents from the following media as Native, the resulting file type is as follows:
|
Original Media |
Content Source |
Resulting File Type |
|
Facebook IM |
Socialite |
HTML |
|
Facebook Posts |
Socialite |
HTML |
|
|
Socialite |
HTML |
|
Bloomberg IM |
Vantage |
HTML |
|
Bloomberg IM |
API |
HTML |
|
Bloomberg EML |
Vantage |
|
|
Bloomberg EML |
API |
|
|
Outlook |
EGW |
EML |
|
MSG Files |
ITM XML |
If attribute under ITM XML is as follows: MS-OXProps-Version =<"1" "2" or "3"> MS-OXProps-Message ="<any value>" Native Output: MSG Else, Native Output: EML |
|
EML Files |
ITM XML |
EML |
In a CSV export, Bcc participants are only limited to 50.
When a document containing multiple participants (for example, more than 500 in the To/Cc/Bcc fields) is exported as CSV, the participants listing in the file gets truncated to multiple rows. This is Microsoft Excel issue. As a workaround, Smarsh recommends to use Notepad++ to view such CSV files.
Exported CSV files for Tier 2 data support the following fields:
snapshot_time (Represents the sent time of the message as displayed in the UI)
files_count
archived_time
subject
users_to_cc_bcc
users_bcc
gcid
channel
messageId
interaction_id
network
transcript_id
users_from
users_to
users_cc
key
cms_collected_item_id
cms_hold_flag
If the size of an exported package exceeds
1 GB
, the package is divided into multiple chunks. This applies for both ZIP and PST files, and each chunk will not exceed 1 GB in size.
The UI displays the progress for long-running exports, particularly for exports larger than 4 GB. A notification message will indicate that a large export is in progress and may take longer to complete.
Scheduled Exports
In a typical Disaster Recovery (Failover(FO)/Failback(FB)) setup in Enterprise Archive, upon failover to the Secondary site, ongoing scheduled exports will not continue by default and remains in a Failed state. This is because there will be no DR event created and the Secondary site will not understand nor will have any information about the ongoing export and its progress.
As a mitigation plan, for the frequently triggered scheduled exports to continue or to not lose any data due to site swap (FO/FB), Smarsh SRE team will perform certain configurations manually on the scheduled exports template. This will enable the ongoing scheduled export to resume and also ensure that the delta of Failed documents are synced to the Secondary site.
Limitations
Here are a few limitations that are observed once the synchronization is complete:
When documents are filtered/searched with a specific “Date Range”, the search results will be different in the Primary and Secondary site. The results will not match as the processed/archive time of the documents on both the sites are different. That is, same documents that are a part of the Primary site for a specified date range cannot be expected in Secondary site. This also corresponds to any lag for items being archived in Primary site and within 72 hours on the Secondary site.
When there are no documents available for a specified date or date range in the DR but was available in Primary before the DR event, it implies that synchronization between Primary and Secondary wasn't completed. In such cases any exports for that date or date range will complete with zero documents.
The different in time is there between the Primary and Secondary site cannot be derived beforehand.
Administration
The following variables in Enterprise Archive can are exposed to create your own Alert or Notifications templates.
|
Variables Used |
Description |
|
${BRANDNAME} |
Brand name used for the product, which is Communications Intelligence Platform. |
|
${FIRSTNAME} |
First Name of the user to whom these alert emails are triggered. |
|
${LASTNAME} |
Second Name of the user to whom these alert emails are triggered. |
|
${URL} |
Link to a corresponding page for the user to click for more information. |
|
${EMAIL} |
Email address of the user. |
|
{PWDIMAGENAME} |
Image where users temporary password is displayed. |
|
${QUERYNAME} |
Name of a Supervision policy. |
|
{QUEUECREATOR} |
Name of the user who created the Supervision Policy. |
|
${ACTUALHITS} |
Number of policy hits. That is, the total number of matches in words or phrases according to the Supervision policy. |
|
${CIRCUITBREAKERLIMIT} |
The specified circuit breaker limit for Flag policies. |
|
${REPORTNAME} |
Name of the report selected while creating a scheduled export. |
|
${MODE_OF_SCHEDULE} |
The mode of schedule used for the report such as, Run Once, Run Frequently, or Run Now. |
|
${TIME_ZONE} |
The time zone set for the scheduled report. |
|
${DATE_RANGE} |
The date range specified for the scheduled report. |
|
${EXPORT_NAME} |
Name of the export defined while creating an export job. |
|
${STATUS} |
The status of the export job, such as Successful, Failed, or Disposed. |
|
${SCHEDULE_REPORT_NAME} |
Name of the report defined by the user while creating a scheduled export. |
|
${REPORT_COUNT} |
Number of reports failed to generate. |
|
${FAILURE_SUMMARY} |
Summary of failed reports. |
|
${QUEUENAME} |
Name of a Queue in a Supervision policy. |
|
{MIN_CHARS_BEFORE_WILDCARD} |
The minimum number of characters set for wild card search to initiate. That is, in Enterprise Archive, the character limit is three by default. Therefore a wildcard search will function only if there are a minimum of three characters before a wildcard. |
You can track all create, update, and delete operations performed in Enterprise Archive UI by looking viewing the User Activity Logs. Password updates and reset can also be tracked by enabling the Update check-box under the Actions section.
The following cookies are used by Enterprise Archive:
|
Cookie Type |
Name |
Description |
|
Persistence (1000 days) |
saved-theme |
Selected UI theme (Defaults to ' alcatraz '). |
|
Persistence (1000 days) |
tf |
User preference - Time Format |
|
Persistence (1000 days) |
tz |
User preference - Timezone |
|
Session |
uuid |
Session ID |
|
Persistence (10000 days) |
validLogin |
Boolean value to check valid login. |
|
Session |
xdcc |
Double Cookie Check Token to avoid CSRF attack. |
Archive Management
Retention policy deals with defining and managing retention periods for the archived data. Retention management allows an administrator to retain data in the archive, only for the required duration. Retention periods must be managed to ensure that data is stored in the archive only as long as it is necessary for the organization. Retention management also ensures that data is not removed prematurely by accident before the retention period expires.
Post Enron crisis, Federal Rules of Civil Procedures (FRCP) amendments required organizations to preserve Electronically Stored Information (ESI) of employees when there is a reasonable anticipation of litigation between communicating parties. ESI can be preserved at both document and employee (or custodian) level.
Preservation Policy allows organizational level hold to be placed on certain custodians whose content needs to be protected at all times with or without being associated to cases. Preservation Policies also provides an efficient mechanism to ensure content is protected quickly without competing with disposition when millions of documents need to be put on hold. The Preservation Policies do not completely eliminate the risk from losing documents to disposition process but significantly reduce the risks. The document level preservation in Enterprise Archive is Legal Hold.
Even though the configured retention policy expires, the document will not be deleted or disposed since the participant is on prevervation hold.
Example
|
Document Status |
Disposition Status after 30 days |
|
Start Time: Jan 01, 2022 Retention Policy: 30 Days Preservation/Custodian hold Status: Applied |
DOCUMENT NOT DISPOSED When disposition triggers on 1st Feb 2022, the document will not be deleted or disposed since participant is on preservation hold. |
The document will be deleted or disposed.
Example
|
Document Status |
Disposition Status after 30 days |
|
Start Time: Jan 01, 2022 Retention Policy: 30 Days Preservation/Custodian hold Status: Removed |
DOCUMENT DISPOSED When disposition triggers on 1st Feb 2022, the document will be deleted or disposed. |
Case Management
If a message in a Case has two participants that have different retention values set, what is the expected behavior?
Use Case
Case1 has a message with two participants (Brandon and Jeremy). Brandon's participant has a retention period set of 3 days. Jeremy's is 1 day. There are two reviewers on the Case - Reviewer1 and Reviewer2.
Questions
If the message has both participants, Brandon and Jeremy, after day 1, is the message purged?
If Reviewer1 (reviewer on the case) is restricted by his role to see only Jeremy (restriction policy), would Reviewer1 still see the message in the case after day one? If the retention period expires for Jeremy, is that message still returned when Reviewer1 searches.
Answer
The message would not be purged because Brandon's participant has a retention of 3 days. The message goes by lengthiest retention period.
Yes, Reviewer1 will be able to see the messages when searched.
A message is given various Retention Policies over its life cycle in the archive. In this case, it would have a 3-day retention period for Brandon, and a separate 1-day retention period for Jeremy.
If it was hit by supervision it may have a Supervision Queue driven retention period. Purge works by looking nightly for documents that no longer have ANY valid retention periods. Thus, as long as there is one valid retention period the message will not be purged. If the message is not purged, the message is still surfaced in all the different applications where it has been presented throughout the application. Therefore, the retention period in Supervision may expire, but there is a hold, or separate retention period that maintains the record. That record remains available in Supervision until all policies expire. Participant targeted retention periods have no bearing on the searches performed. The document is available and can be search by any of its attributes.
Private tags groups, also known as case specific tag groups are visible only within a particular case. Private tags are confidential tags such as sexual harassment, racism, or employee termination and so on. Such tags must not be exposed to other case reviewers and hence private tags are visible only within a particular case.
Note
Private tags are not displayed in the reports as well.
For more information on how to create case specific tag group, see Creating Tag Groups and Adding Tags.
Supervision
No, it is not mandatory for the user to use sampling profiles to filter participants/groups. Random selection will be employed if no sampling or policies are applied. For more information on Sampling Profile, see Configuring Sampling Profiles.
A circuit breaker is a limit specified in the Supervision application while configuring a Queue. The Supervision policy executing that queue is disabled beyond the configured limit. The following behavior is observed in a Supervision Flag and Ignore policy:
Circuit Breakers are designed to limit the maximum number of documents that can be flagged/ignored by a policy for a given queue. The aim of circuit breakers is to prevent policies from unnecessarily flooding review queues, with a large number of documents. This in turn will protect the SLAs defined for Queue completion in the system.
Flag Policies: The circuit breaker limit for Flag policies is specified in Enterprise Conduct. Enterprise Conduct disables a policy when it enters a circuit breaker situation. A circuit breaker situation arises when the number of documents that a policy can fetch exceeds the maximum number of documents defined in the Disable policy when reaching a max of <text box> hits parameter. In this scenario, no documents are fetched by the policy, the policy gets disabled, and the status of the policy changes to Disabled by system, and an email notification is sent to the queue creator. For example, the criteria of a policy is such that it is able to fetch 5000 documents, but the parameter Disable policy when reaching a max of <text box> hits is set to 2000. In such a case, when the policy runs and exceeds the limit of 2000 documents, it enters a circuit breaker situation, and gets disabled.
Ignore Policies: The circuit breaker limit for Ignore policies is set to 500000 by default. This is controlled by a server property setting. If the documents being returned exceed the circuit breaker limit for Ignore policies, Enterprise Conduct will disable the Queue and issue an email notification to the user regarding the same.
Note
When a conversation comes into a queue, and you delete the policy that had fetched that conversation, then the conversation continues to stay in the queue. This conversation is removed from the queue after you have completed the Conduct process by closing the conversation.
If a conversation is fetched by multiple policies, then the conversation is displayed in the queue only once. In this case, the Matched policy panel displays all the policies that fetched the conversation, and all policy types are displayed.